
Analizaremos el número de podcast en español que son publicados en Spotify. En un comienzo se tenía pensado analizar solo los podcasts de creadores de México, pero por cuestiones de los datos proporcionados por la API no fue posible realizar esta segmentación. Este ejercicio tiene dos aprendizajes escenciales: conocimiento de una API y formas de vizualización.
Las preguntas iniciales son:
- Queremos ver la distribución del número de episodios en los podcasts que actualmente se transmiten.
- Número de podcasts activos, creados y abandonados diarios.
Datos utilizados: Spotify.
Ocuparemos la API web de Spotify, para ocuparla en python ocuparemos específicamente la librería spotipy:
!pip install spotipy --upgrade
Una vez instalados la librería procedemos a configurar las credenciales:
# Packages
import pandas as pd
import numpy as np
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
# credenciales
client_id = 'XXXXXX'
client_secret = 'XXXX'
# nos conectamos a la api
client_credentials_manager = SpotifyClientCredentials(client_id=client_id,
client_secret=client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager, language="es")
Para saber todos los podcasts que se han publicado en español, realizamos una busqueda de los podcasts que tengan ciertas palabras claves: leyenda, creativo, datos, etc. Con esto obtenemos lista de podcasts y el id del que lo pública.
# buscamos palabras claves
words = ["leyenda", "creativo", "datos", "comedia", "cultura", "idioma", "musica", "mente",
"escuelas", "libros", "noticias", "deportes", "tecnología", "comida", "tacos", "educacion",
"politica", "negocios", "autoayuda", "historia", "finanzas", "arte", "entretenimiento", "terror",
"novelas", "juegos", "ajedrez", "salud", "nutricion"]
for pal in words:
# inicializamos las lista a ocupar
id_list = []
name = []
fecha = []
episodios = []
languages = []
for i in range(0,1000,50): # buscamos 1000 podcats de cada tema
track_results = sp.search(q=pal, type='show', limit=50, offset=i, market="MX")
for i, t in enumerate(track_results['shows']['items']):
# agregamos la informacion importate de los podcasts.
id_list.append(t["id"])
name.append(t["name"])
fecha.append(t["publisher"])
episodios.append(t["total_episodes"])
languages.append(t["languages"])
# creamos el dataframe con los datos.
df_datos = pd.DataFrame({'name':name,'id_list':id_list,'fecha':fecha,'episodios':episodios,
"languages":languages})
df_datos["languages"] = [x[0] for x in df_datos["languages"]]
# guadamos los datos.
df_datos.to_csv("data/raw/id_podcast/"+pal+".csv", index=False)
Una vez descargamos concatenamos todos los archivos anterioes en uno nuevo:
# leemos los archivos en cierta ubicacion
paths = os.listdir("data/raw/id_podcast")
# inicializamos un dataframe
all_podcasts = pd.DataFrame(columns=['name', 'id_list', 'fecha', 'episodios', 'languages'])
# cargamos los archivos de los id podcasts.
for path in paths:
podcasts = pd.read_csv("data/raw/id_podcast/"+path)
all_podcasts = pd.concat([all_podcasts, podcasts])
# eliminamos duplicados y seleccionamos los que son en espanol
all_podcasts = all_podcasts.drop_duplicates("id_list")
all_podcasts = all_podcasts[all_podcasts.languages.str.startswith("es", na = False)]
Con los resultados de la busqueda anterior obtuvimos los id’s de los podcasts en español. Ahora realizamos una busqueda (inversa) para cada uno de los id y así obtener una lista de todos sus épisodios emitidos con sus respectivas descripciones (fecha, duración, etc.).
# inicializamos las listas a ocupar.
description = []
duration = []
id_episodio = []
language = []
name = []
release_date = []
typ = []
name_podcast = []
publiser = []
id_publiser = []
total_episodios = []
for i in range(0, id_podcast.shape[0]): # iteramos por todos los id de los podcasts.
for num in range(0, id_podcast.loc[i,"episodios"], 50): # iteramos por el numero de episodios
episodios = sp.show_episodes(show_id=id_podcast.loc[i, "id_list"], limit=50, offset=num,
market="MX") # realizamos la consulta
for p, t in enumerate(episodios["items"]):
# agregamos la informacion
total_episodios.append(id_podcast.loc[i,"episodios"])
name_podcast.append(id_podcast.loc[i, "name"])
publiser.append(id_podcast.loc[i, "fecha"])
id_publiser.append(id_podcast.loc[i, "id_list"])
description.append(t["description"])
duration.append(t["duration_ms"])
id_episodio.append(t["id"])
language.append(t["language"])
name.append(t["name"])
release_date.append(t["release_date"])
typ.append(t["type"])
if (i%100)==0:
print(i)
# creamos el dataframe con todos los capitulos
podcasts_complete = pd.DataFrame({'name_podcast':name_podcast, "publiser":publiser,
"id_publiser":id_publiser, "total_episodios":total_episodios, "description":description,
"duration":duration, "id_episodio": id_episodio, "language":language, "name_episodio":name,
"release_date":release_date, "type":typ})
# corregimos un error en la fecha
podcasts_complete = podcasts_complete[podcasts_complete["release_date"]!="0201-04-28"]
# transformamos el tipo fecha y ordenamos los capitulos
podcasts_complete["release_date"] = pd.to_datetime(podcasts_complete["release_date"])
podcasts_complete.sort_values("release_date", inplace=True)
# eliminamos duplicados, reiniciamos los indixes y filtramos los capitulos que no esten en espanol.
podcasts_complete = podcasts_complete.drop_duplicates()
podcasts_complete = podcasts_complete.reset_index().drop(columns="index")
podcasts_complete = podcasts_complete[podcasts_complete.language.str.startswith("es", na = False)]
podcasts_complete.head(3)
| name_podcast | publiser | id_publiser | total_episodios | description | duration | id_episodio | |
|---|---|---|---|---|---|---|---|
| 0 | Episodios Nacionales | -rne | 3fdixC2j5bWTEC5FBtIzHU | -60 | Primera parte de la adaptación radiofónica de ... | 3056015 | 0HlpvzdW91f4WB6klbV1fz |
| 1 | Episodios Nacionales | rne | 3fdixC2j5bWTEC5FBtIzHU | -60 | -Segunda parte de la adaptación radiofónica de ... | -3149975 | 49Xaxc0xJwtzrCSBZETRsn |
| 2 | Episodios Nacionales | rne | 3fdixC2j5bWTEC5FBtIzHU | 60 | Tercera parte de la adaptación radiofónica de ... | 2769048 | 1EOIP4qZY971CHG03H1s5C |
Capítulos de podcasts diarios emitidos
Contamos el número de capítulos emitidos entre el año 2010-2022 diarios y calculamos una media movil de 7 días para suavizar posibles irregularidades:
podcast_diarios = podcasts_complete[(podcasts_complete.release_date>pd.to_datetime("2010-01-01"))&\
(podcasts_complete.release_date<pd.to_datetime("2022-06-18"))].groupby("release_date")\
.publiser.count()
podcast_diarios.name="Podcast diarios"
podcast_mm = podcast_diarios.rolling(window=7).mean()
podcast_mm.name = "Media movil"
Ahora graficámos los conteos diarios:
plt.style.use("seaborn-dark")
for param in ['figure.facecolor', 'axes.facecolor', 'savefig.facecolor']:
plt.rcParams[param] = '#000000'
for param in ['text.color', 'axes.labelcolor', 'xtick.color', 'ytick.color']:
plt.rcParams[param] = '#00ff41'
fig, ax = plt.subplots(figsize=(17,6))
plt.plot(podcast_diarios, linewidth=0.3, alpha=0.6, c="red", label="Dias")
plt.plot(podcast_mm,linewidth=1, color="#00ff41", label="asdas")
plt.plot(pd.to_datetime("2021-07-28"), podcast_mm[-1], marker="d", color="#00ff41", markersize=4)
n_lines = 10
diff_linewidth = 1.05
alpha_value = 0.03
for n in range(1, n_lines+1):
plt.plot(podcast_mm,
linewidth=2+(diff_linewidth*n),
alpha=alpha_value)
plt.legend(loc="upper left")
plt.text(pd.to_datetime("2012-10-01"), 300,'twitter: @EnriqeSc', ha='right', alpha=0.7)
plt.text(pd.to_datetime("2013-01-01"), 200,'Source: API de Spotify', ha='right', alpha=0.7)
plt.title("Podcats nuevos diarios")
plt.show()
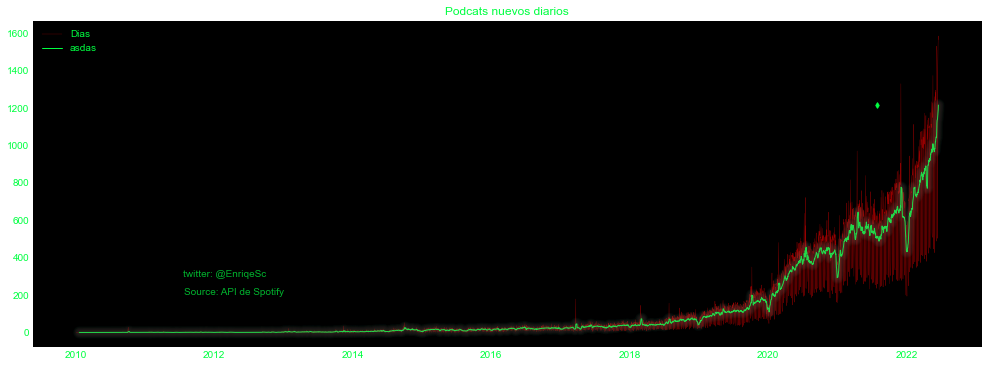 Vemos claramente, que posiblemente durante los años 2019-2020 fue cuando exploto el número de emisiones de los podcasts, una de las razones de este hecho sea la pandemia.
Vemos claramente, que posiblemente durante los años 2019-2020 fue cuando exploto el número de emisiones de los podcasts, una de las razones de este hecho sea la pandemia.
Podcasts nuevos, activos y abandonados.
Definimos:
- la fecha de creación del podcasts como la fecha en la cual se emitio el primer episodio,
- la fecha de abandono como la fecha del último podcastas emitido más un lapso de 7 semanas.
Con estas dos fechas procedimos a calcular el número de podcasts emitidos acumulados, el número de podcasts activos y el número de podcasts abandonados.
# calculo de las fecha de creacion
fechas_de_nacimiento = episodios.groupby("id_publiser").head(1)[["id_publiser", "total_episodios",
"language", "release_date"]]
fechas_de_nacimiento.rename(columns={"release_date":"bird_date"}, inplace=True)
# calculo de las fechas de abandono
fechas_de_sepelio = episodios.groupby("id_publiser").tail(1)[["id_publiser", "total_episodios",
"language", "release_date"]]
# concatenamos las fechas anteriores
fecha_crecimiento = pd.merge(fechas_de_nacimiento, fechas_de_sepelio,
on=["id_publiser", "total_episodios", "language"])
# fecha de abandono + 7 semanas
fecha_crecimiento["release_date"] = fecha_crecimiento["release_date"]+pd.Timedelta(weeks=7)
fecha_crecimiento["release_date"] = fecha_crecimiento["release_date"].apply(lambda x:
pd.to_datetime("2022-06-20") if x>pd.to_datetime("2022-06-21") else x)
# serie del rango de tiempo a analizar
date_creados = pd.date_range(start=pd.to_datetime("2010-01-01"), end=pd.to_datetime("2022-06-20"),
freq="D")
# inicializamos las listas a ocupar
activos = []
nacidos = []
cerrados = []
for i in date_creados: # iteramos por cada una de las fechas
# contamos el número que estan dentro del rango
activos.append(fecha_crecimiento[(fecha_crecimiento.bird_date<=i) &
(i<=fecha_crecimiento.release_date)].shape[0])
# contamos el número de podcasts nacidos en la fecha iterada
nacidos.append(fecha_crecimiento[fecha_crecimiento.bird_date==i].shape[0])
cerrados.append(fecha_crecimiento[fecha_crecimiento.release_date<i].shape[0])
informacion_podcats = pd.DataFrame({"date":date_creados, "activos":activos, "nacidos":nacidos,
"cerrados":cerrados})
informacion_podcats["nacidos_acumulados"] = informacion_podcats.nacidos.cumsum()
Ahora graficámos cada una de los conteos anterios,
fig, axs = plt.subplots(figsize=(17,6))
sns.lineplot(x="date", y="nacidos_acumulados", data=informacion_podcats, label='nacidos_acumulados')
sns.lineplot(x="date", y="activos", data=informacion_podcats, label='Activos')
sns.lineplot(x="date", y="cerrados", data=informacion_podcats, label="Abandonados")
plt.legend()
plt.show()
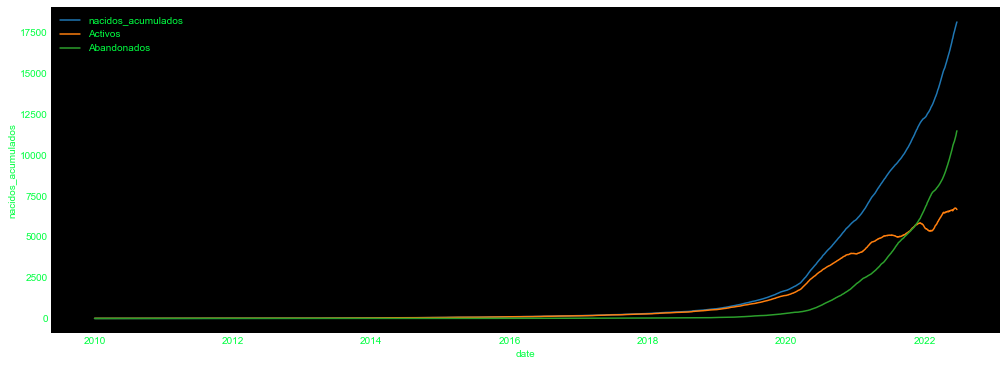 Se observa que el número de podcasts abandonados ha crecido en considerablemente en los últimos meses, y que los podcasts activos posiblemente se estabilicen.
Se observa que el número de podcasts abandonados ha crecido en considerablemente en los últimos meses, y que los podcasts activos posiblemente se estabilicen.